Over the last two years, a consistent narrative has taken hold across the software industry: AI will write the code, review pull requests, perform architecture reviews, conduct threat modelling, and ultimately secure applications. Recent industry data supports that direction. In GitLab’s 2026 Global DevSecOps research, 76% of respondents believe AI-assisted coding will require more engineers rather than fewer, and 43% rank implementing AI for security and compliance as the top skill for career advancement — ahead of using AI for code generation (GitLab DevSecOps Report 2026; press summary). If that plays out, the obvious question is whether security engineers still need deep security expertise. The answer is yes — and the reality is the opposite of what most people assume.
As AI systems grow more capable, the value of security engineering knowledge does not diminish — it increases substantially. Not because humans will continue performing every review manually, but because the professionals who understand security most deeply will be the ones responsible for teaching, constraining, validating, and scaling the AI systems that perform those reviews on their behalf. The future security engineer will not simply conduct security reviews; they will build security reviewers.
Table of Contents
- The Previous Era
- AI as a Security Assistant
- Engineering Constraints
- AI Amplifies the Posture You Already Have
- Security Knowledge Becomes Executable
- Why Secure-by-Design Becomes the Foundation
- From Individual Reviews to Scalable Security Systems
- The New Capability Security Teams Need
- The Engineers Who Lead This Forward
The Previous Era: Humans as the Execution Layer
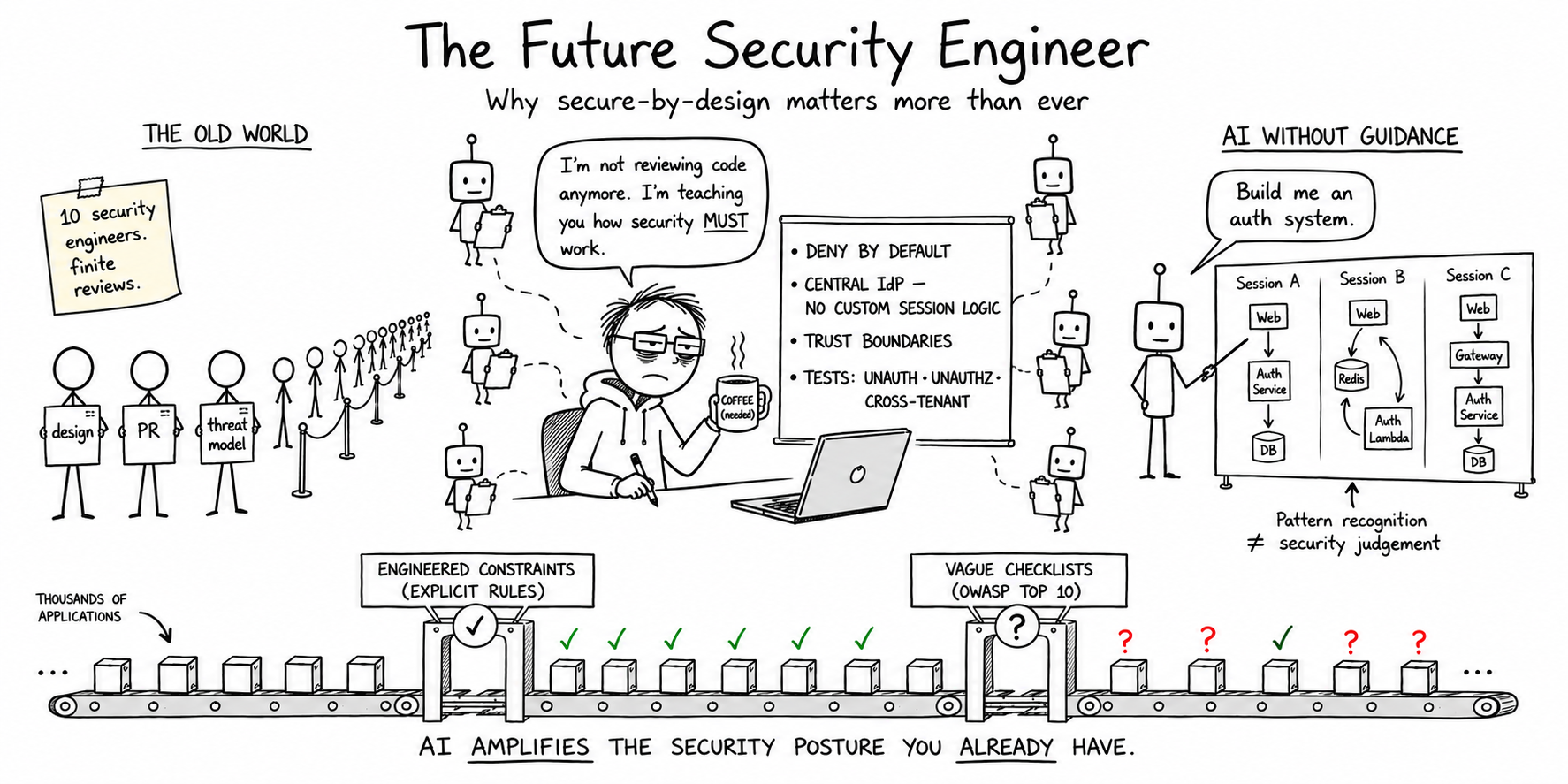
For the past two decades, most application security programmes operated on a straightforward model: security engineers developed deep expertise in secure-by-design principles, threat modelling, authentication and authorisation, cryptography, architecture review, and risk assessment, then applied that expertise directly to each engagement — a design review, a pull request, or a threat model against a new architecture.
Consider what that looked like in practice. A team building a payments service would engage a security engineer who reviewed data flow diagrams, identified where cardholder data crossed trust boundaries, challenged whether the tokenisation strategy was sound, and assessed whether the authorisation model prevented horizontal privilege escalation between accounts. That work takes time, queues build, and the next team waits. Community benchmarking from the inaugural State of Threat Modeling 2024–2025 report (published August 2025) found that producing 10–100 threat models per year puts most organisations in line with their peers — and 52% still have no regular threat-model reporting to management.
Security knowledge lived primarily in the heads of experienced practitioners, which meant the fundamental constraint was always human scale. An organisation with ten security engineers could produce only a finite number of reviews, and every additional unit of security coverage required additional human effort. That imbalance is now widening as AI accelerates output: September 2025 enterprise telemetry across Fortune 50 organisations found AI-assisted developers committing at three to four times the rate of peers while security findings rose roughly tenfold over six months (enterprise study, Sep 2025). This tension between security coverage and available headcount shaped how most AppSec programmes were built — and it remains the dominant operating model today.
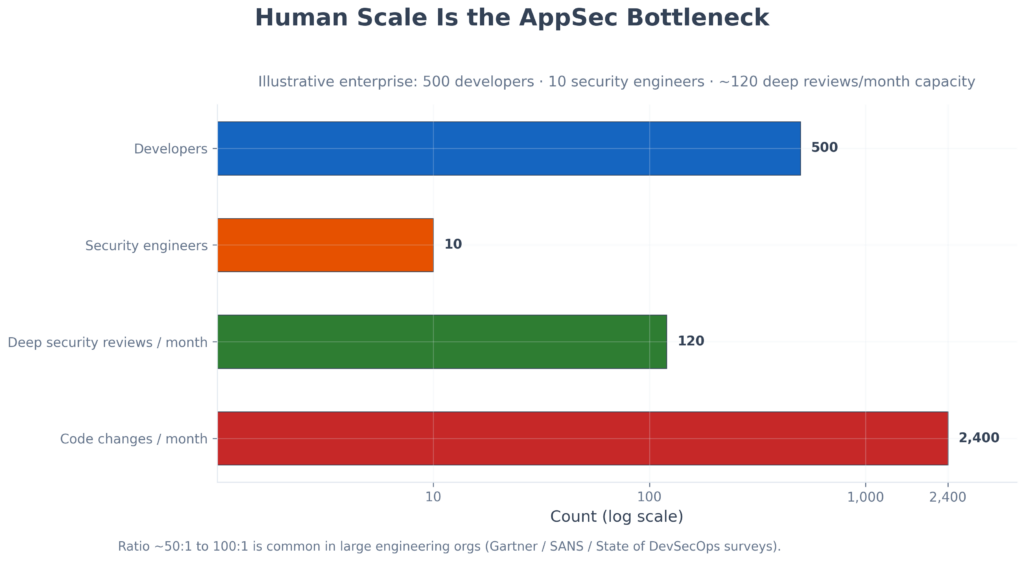
Illustrative enterprise model: ~500 developers, ~10 security engineers, and roughly 120 deep security reviews per month against thousands of code changes. The capacity gap is supported by 2025–2026 industry data (4× velocity / 10× findings; GitLab compliance-after-deployment findings).
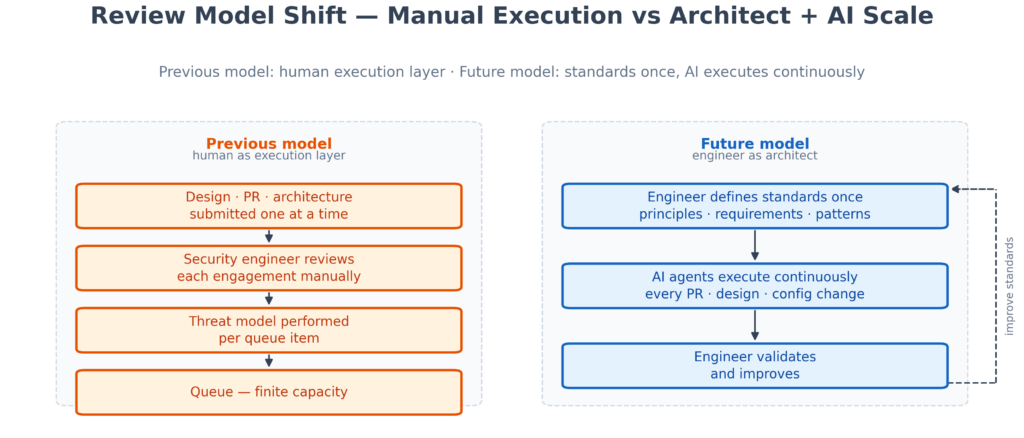
Previous model: security engineers as the execution layer, one review at a time. Future model: engineers define standards once; AI executes continuously across the SDLC.
AI as a Security Assistant: Capability and Its Limits
AI is now capable of meaningfully assisting security work. It can review source code for common vulnerability classes, analyse infrastructure-as-code configurations for misconfigurations, produce initial threat model drafts, identify architectural weaknesses, and explain vulnerabilities in the context of a specific codebase. For teams stretched thin across a large development organisation, that assistance has real operational value — but 2025–2026 empirical research shows a persistent security gap when output is accepted without validation. A multi-model benchmark across more than 100 LLMs and 80 security-sensitive coding tasks found only a 55% security pass rate — meaning 45% of generations introduced known flaws without security-specific guidance (GenAI code security report, 2025). That rate remained flat into early 2026 (follow-up assessment, Spring 2026).
The hard limit practitioners encounter quickly is that AI does not possess security judgement — it possesses pattern recognition, and the distinction matters enormously in practice. The OWASP Top 10 for LLM applications flags overreliance and insecure output handling as first-class risks precisely because models can produce plausible but unsafe implementations when outputs are not validated against organisational requirements. Ask an AI to design an authentication system with no further constraints, and the answer will differ meaningfully based on how the prompt was phrased, which examples dominated its training data, and what surrounding context was provided. One session produces an implementation built on the existing identity provider with central session management. Another produces a custom session token with its own storage logic and no test coverage for cross-tenant access — the kind of gap that maps to CWE-306 (missing authentication) or CWE-639 (broken authorisation across tenants). Both may look internally consistent. Only one follows the architecture pattern the organisation actually requires.
The root cause is not a lack of capability but a lack of context. Without explicit guidance, AI has no awareness of an organisation’s risk appetite, regulatory obligations, data classification requirements, or what “acceptable” looks like for a given architecture. In the absence of that input, it defaults to what appears reasonable — and reasonable is not the same as secure.
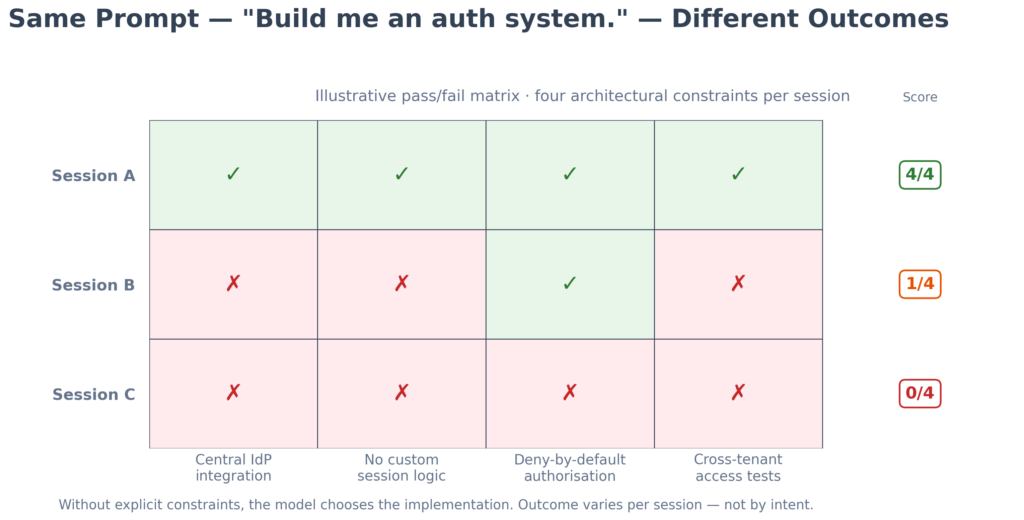
Illustrative pass/fail matrix: three sessions against the same prompt (“Build me an auth system.”) checked against four architectural constraints (4/4 · 1/4 · 0/4). Without explicit guidance, compliance varies by session — not by intent.
Engineering Constraints, Not Risk Categories
The most common mistake practitioners make when writing security instructions for AI coding assistants is starting with the OWASP Top 10. This is not because the Top 10 is wrong — it is accurate, well-researched, and remains a useful risk reference. The problem is that it describes risk categories, not engineering constraints. Risk categories tell you what can go wrong. Engineering constraints tell the system how it must be built — the same distinction ENISA’s March 2026 Security by Design and Default Playbook draws when it maps principles to repeatable engineering actions, evidence requirements, and release-gate criteria rather than vulnerability labels alone.
A vague prompt leaves the model to choose the implementation:
"Make sure this app is secure against XSS, SQL injection and broken access control."Sometimes that produces framework-native escaping; sometimes custom sanitisation or regex-based filtering; sometimes something that looks secure until someone reviews it under adversarial conditions. The same problem compounds at the authentication level:
"Build me an auth system."This will produce something. It may produce something reasonable. But without constraints, there is no guarantee it integrates with the existing identity provider, avoids reimplementing password storage from scratch, enforces deny-by-default access control, or includes test coverage for unauthenticated, unauthorised, and cross-tenant access scenarios.
The constrained versions look entirely different. For authentication:
"Integrate with the existing central identity provider. Do not implement password
storage or session logic from scratch. Add a central authentication and authorisation
layer. Protected routes must deny by default unless an explicit policy allows access.
Add tests for unauthenticated, unauthorised and cross-tenant access."For injection — the same vague Top 10 prompt from above, rewritten as build requirements:
"Use the ORM for all database access — no raw SQL. Use framework-native output
encoding for all user-controlled data — no custom sanitisation or regex filters.
Set a Content-Security-Policy header on every response. Add tests that confirm
parameterised queries and escaped output on representative endpoints."That is the shift. From vulnerability names to proactive controls. From “please make it secure” to “build it this way, with these constraints, and prove it with tests.” Writing instructions at that level of precision requires exactly the engineering knowledge that security professionals have historically developed through hands-on architecture work: understanding which controls must be centralised, how trust boundaries are enforced, what deny-by-default means in a specific system, and which test scenarios prove a control is actually working rather than merely present.
The same translation applies across the OWASP Top 10. The categories describe what can go wrong; engineering constraints describe how the system must be built:
| OWASP category | Engineering constraint for AI |
|---|---|
| A07 — Identification & Authentication Failures | Integrate with central IdP. No custom session logic. Deny-by-default on all protected routes. Tests required for unauthenticated and cross-tenant access. |
| A01 — Broken Access Control | Authorisation enforced at a central layer, not in individual controllers. Every endpoint requires an explicit allow policy. Implicit access is always denied. |
| A03 — Injection (XSS, SQLi) | ORM for all database queries — no raw SQL. Framework-native output encoding — no custom sanitisation or regex. Content Security Policy header required on all responses. |
| A02 — Cryptographic Failures | All PII encrypted at rest using AES-256 or platform-managed keys. TLS 1.2+ enforced in transit. No deprecated algorithms. Secrets management via vault — no hardcoded credentials. |
Four illustrative mappings; the same risk-category-to-constraint translation applies across the full Top 10.
Production teams are already publishing this pattern. OpenAI documents sandboxing and network allowlists for Codex (Running Codex safely); Trail of Bits ships a reference config for Claude Code with permissions, hooks, and MCP defaults (claude-code-config). The vocabulary differs; the idea is the same — constraints, not categories.
AI Amplifies the Posture You Already Have
Many organisations are approaching AI adoption with the assumption that AI will compensate for gaps in security engineering maturity. The evidence points consistently in the opposite direction: AI amplifies the security posture you already have. When code volume accelerates faster than security headcount, the capacity gap widens rather than closes — the same 4× velocity / 10× findings pattern from Fortune 50 telemetry through 2025 (enterprise study, Sep 2025). CSA’s April 2026 research note documents the same structural pattern as “security debt” accumulating faster than remediation (CSA, Vibe Coding’s Security Debt).
Consider two organisations deploying the same AI security tooling. Organisation A has mature secure-by-design practices: engineers who can articulate trust boundaries, define threat actors, apply established architecture patterns, and write testable security requirements. They use AI to scale that expertise — reviewing more designs in less time without reducing quality — and their agent instructions reflect real decisions about identity, secrets management, and which vulnerability classes the platform eliminates by design. Organisation B lacks that foundation. Security work is informal and hard to articulate; GitLab’s 2026 survey found 76% of teams discovering more compliance issues after deployment than during development, consistent with weak upstream requirements surfacing only in production (GitLab press summary). Deploy AI on that backdrop and you automate inconsistency at scale. Same model, sharply divergent outcomes — because the security knowledge directing the AI differs. Recent write-ups echo the split: pipeline-as-code guardrails (Plaid) versus over-privileged agents with no baseline (Cisco OpenClaw analysis).
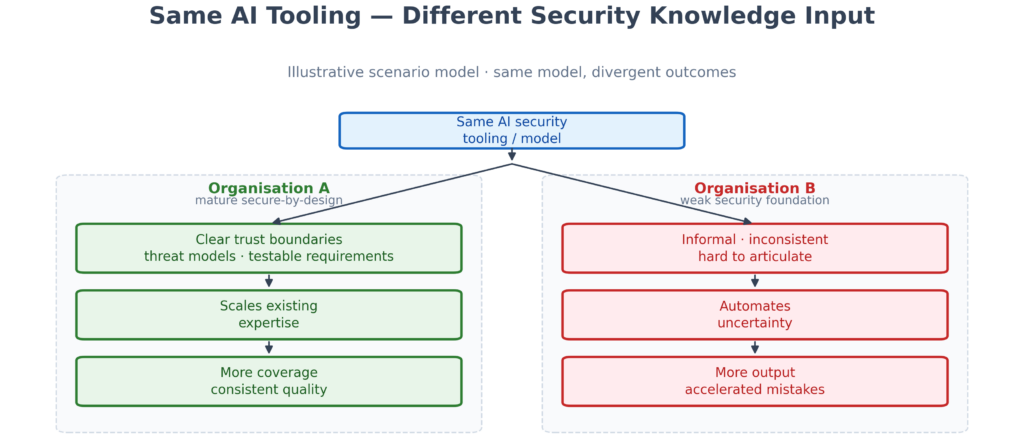
The model is identical. Organisation A scales existing expertise; Organisation B automates uncertainty — outcomes diverge because of the quality of security knowledge directing the AI.
This is the starting point, not the endpoint. Once an organisation understands what it means to direct AI with precision, the next question is how to stop asking AI to find individual vulnerabilities at all — and start building systems where entire vulnerability classes cannot exist.
Security Knowledge Becomes Executable
The most consequential shift is still ahead. Throughout the industry’s history, security knowledge has been encoded primarily in policy documents, design standards, and the accumulated experience of senior practitioners. In the near future, it will increasingly be encoded directly into systems: as security review agents, architecture validation workflows, automated threat modelling pipelines running continuously across the SDLC, and control verification checks embedded in CI/CD.
A team that previously maintained secure coding standards in a PDF can encode those standards as agent instructions and validation rules. Instead of hoping developers read the document — which most do not — the AI checks compliance automatically: flagging endpoints without authorised role checks, database queries that bypass the ORM, cryptographic operations that reach for deprecated algorithms. The same shift applies upstream: one security engineer who previously reviewed a single architecture document can build an agent that reviews thousands; a practitioner who performed threat models manually can create a workflow that generates, validates, and tracks threats from design through deployment.
The most advanced organisations are going further still. Rather than building better review pipelines, they are engineering platforms that make entire vulnerability classes structurally impossible to introduce. SQL injection cannot exist if the platform enforces ORM usage at the build layer. Credential exposure cannot occur if the platform routes all secrets through a vault by default. Cross-tenant data access becomes an architectural impossibility rather than a finding. ENISA’s March 2026 secure-by-design playbook formalises this direction for product teams: 22 principles with checklists, minimum evidence, and release-gate criteria mapped to EU Cyber Resilience Act requirements (ENISA playbook v0.4). This is platform security engineering, and it is where security knowledge at scale ultimately leads.
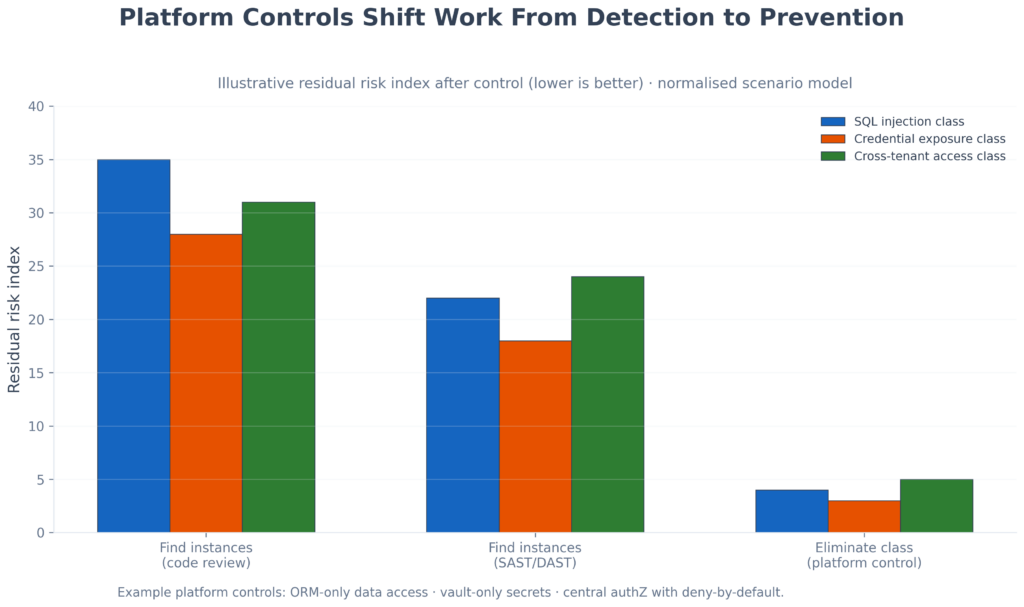
Illustrative residual-risk index: instance detection (review, SAST/DAST) vs platform controls that structurally reduce entire vulnerability classes (ORM-only access, vault-only secrets, central deny-by-default authorisation).
This fundamentally changes the nature of the work. Identifying security issues is no longer the primary challenge — the challenge becomes translating deep security expertise into repeatable, enforceable architecture decisions that prevent entire classes of problems from ever reaching a reviewer.
Why Secure-by-Design Becomes the Foundation
None of this works without a solid security engineering foundation underneath it. Translating risk categories into engineering constraints — see Engineering Constraints — is the first step. The second is making those constraints durable enough to survive automation: written as requirements, not suggestions, so AI outputs can be measured, enforced, and improved rather than re-inferred on every run.
Strong secure-by-design knowledge is what makes that possible. It is what separates a security programme that controls its outcomes from one that hopes for them. The goal is not to allow AI to decide how security should be implemented — the goal is to remove the need for it to decide at all. That case is also economic: architectural flaws are the class of issue most expensive to fix late.
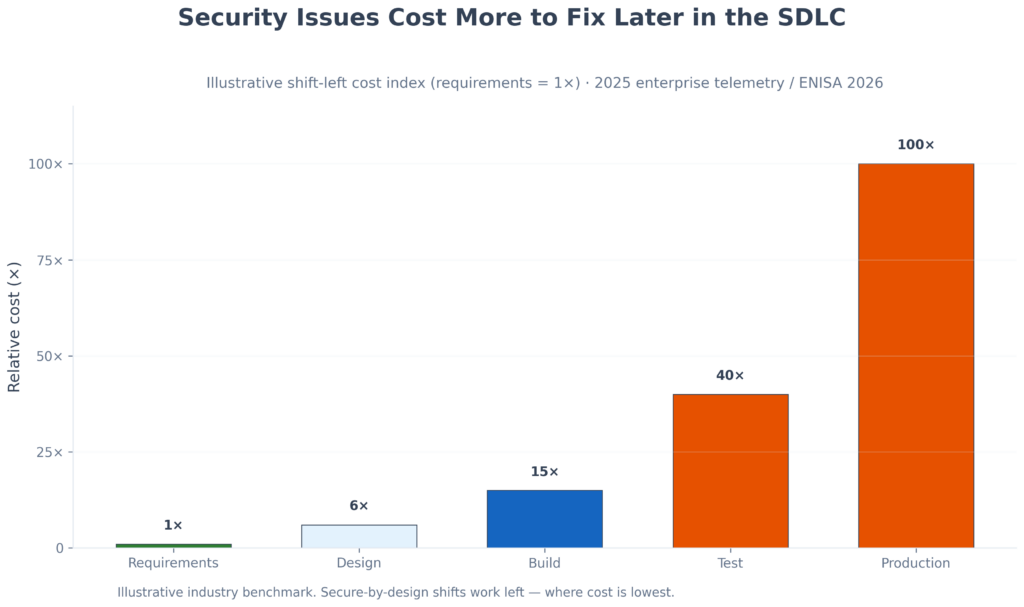
Illustrative shift-left cost index (requirements = 1×). 2025 enterprise telemetry showed architectural design flaws rising 153% in AI-assisted code — the class of issues most expensive to fix late. ENISA’s 2026 playbook places threat modelling and secure defaults at design-phase release gates (ENISA playbook v0.4).
From Individual Reviews to Scalable Security Systems
Organisations experimenting with security agents typically start with the most intuitive prompt: “Review this application for security issues.” The results tend to be inconsistent and difficult to operationalise — not because the model is incapable, but because the prompt provides no baseline against which to evaluate findings, no severity weighting relative to the system’s threat model, and no definition of what acceptable looks like for this architecture. It is the same failure mode as asking a contractor to “make the building safe” without providing a building code.
A more mature approach reframes the role of AI entirely. The security engineer first defines the baseline: the security principles that apply, specific requirements derived from the threat model, approved architecture patterns, the secure coding standards in force, and the review procedure itself. AI is then directed to evaluate whether a given design, codebase, or configuration meets those predefined expectations. In this model, AI is not acting as a security expert exercising independent judgement — it is acting as an executor of security expertise, applying standards that human engineers have already defined. OpenAI’s Codex safety architecture follows the same shape: human-defined sandbox and network allowlists, with an auto-review subagent checking compliance rather than inferring security from scratch (Running Codex safely). The expertise originates from humans; the scale comes from AI — and that distinction separates organisations that control their security outcomes from those that delegate them.
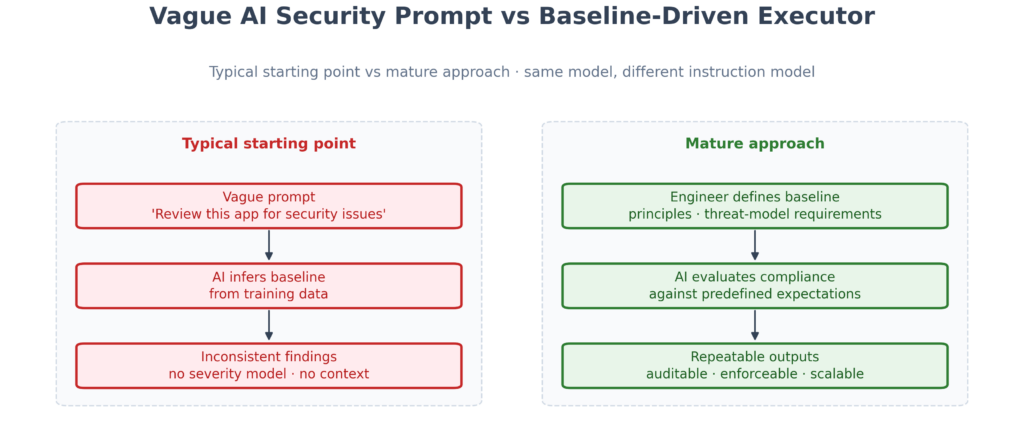
Typical starting point: AI infers the baseline and produces inconsistent findings. Mature approach: engineer defines the baseline; AI evaluates compliance against predefined expectations.
The New Capability Security Teams Need
This shift requires security professionals to develop a capability alongside their technical expertise: knowledge operationalisation — the ability to translate security judgement into structured, reusable instructions that AI systems can follow consistently. Traditional AppSec skills are not going away; if anything they become more valuable as the foundation. Secure-by-design, threat modelling, application security testing, and architecture review remain the core. But they need to be complemented by the ability to write precise agent instructions, design review frameworks, build validation workflows, and define the guardrails that keep AI security outputs within acceptable bounds.
There is a side effect to this shift that is still underappreciated: the same skills required to design secure architecture patterns at scale — understanding where controls must live, how to express requirements precisely enough to be tested, how to define a security baseline that survives team changes — are the same skills required to write effective security rules, coding guardrails, and instructions for AI-assisted development workflows. Secure design patterns are, increasingly, becoming prompt material. ENISA’s 2026 playbook goes further, requiring machine-readable security manifests and verification evidence that security constraints were enforced before release — the same knowledge encoded for humans, now encoded for systems (ENISA playbook v0.4).
| Stage | Output |
|---|---|
| Domain knowledge | Security engineer understands deny-by-default, trust boundary design, authentication patterns |
| Architecture pattern | Expressed as a design standard: “Central auth layer. IdP integration required. No custom session logic.” |
| Enforcement rule | Codified as a review criterion: flag routes without explicit policy, custom session implementations, IdP bypass |
| AI instruction | The same requirement, now executable at scale across every PR, design review, and deployment |
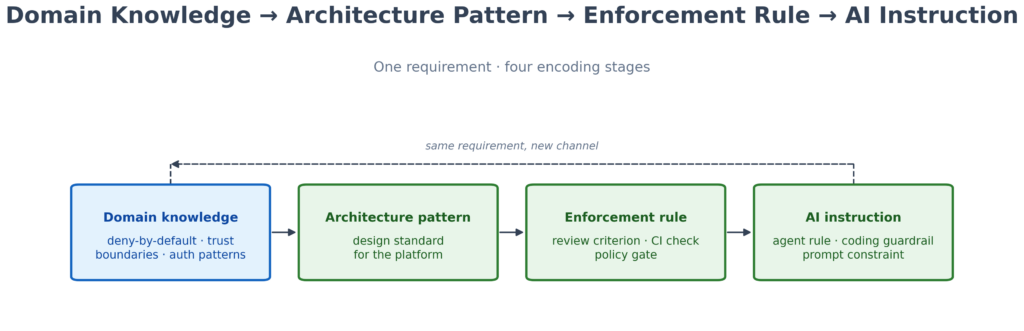
The same security requirement expressed at four stages. The knowledge is identical; only the output channel changes.
Encoded instructions still need a validation loop. Guardrails drift, context changes, models update. Teams treating agents as production systems are adding regression tests for agent behaviour (Microsoft RAMPART), structured AI application testing (OWASP AI Testing Guide), mutation tests to confirm guardrails still hold under shifted prompts (Trail of Bits, 2026), and audit trails for what agents actually executed (trailtool). The security engineer defines the baseline once; validation proves it still holds.
How you know encoding is working — metrics worth tracking once constraints are in place:
- Share of PRs reviewed against a versioned constraint set, not a generic “find vulnerabilities” prompt
- Share of new designs with a threat model recorded before implementation starts
- Share of protected endpoints behind a central authorisation layer with deny-by-default defaults
- Median time from a new secure pattern decision to that pattern appearing in agent rules or CI checks
- False-positive rate on AI-generated security findings — high rates usually mean the baseline is still vague
The organisations that succeed will not necessarily be those with access to the most advanced models. They will be the organisations with the strongest security knowledge encoded into how those models are directed.
The Engineers Who Lead This Forward
AI will accelerate this work, but it will not replace the judgement required to do it well. The security engineer who understands secure-by-design well enough to enforce it across a platform today is the same engineer who will encode it as an instruction set running across thousands of applications tomorrow. The skill does not change; the leverage does — and that is the difference between a security programme that scales and one permanently constrained by headcount.
There is also a harder truth worth stating plainly. The organisations that will struggle most with AI-assisted security are not the ones that adopted AI too slowly. They are the ones that adopted it without first building the security knowledge required to direct it. An AI system that operates without strong security engineering guidance does not produce neutral outputs — it produces outputs that reflect whatever was in its training data and context window, applied to your systems, at scale, without accountability.
The AI is the execution layer. The security engineer is still the architect — the same skill set behind Proactive Security Engineering: Building Secure-by-Design Architectures That Scale, my two-day core training at Black Hat USA 2026 (August 1–2).